Persisting Models in Machine Learning


Day 24 of #100DaysOfCode
This is the continuation of the previous blog. You can read it here: ilkecandan.hashnode.dev/calculating-the-acc..
So far, we have basically done the following: 1- We import our dataset, 2- Make a model. 3- Train it, 4- Request that it make predictions.
Training a model can be time-consuming at times. That is why model persistence is critical. We'll train our model before saving it to a file. When we wish to make predictions again, we simply load the model from the file and ask it to do so. We don't need to retrain that model because it has already been trained.
We should add this module to our code:
import joblib
joblib object has methods for saving and loading models.
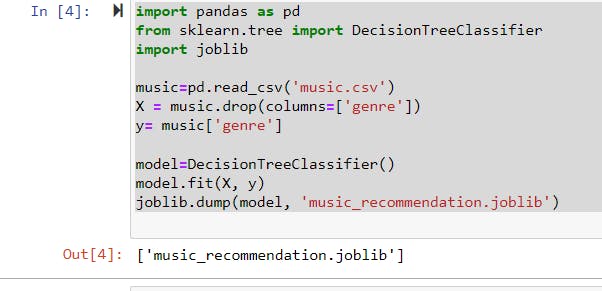
So, our whole code should look like this:
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
import joblib
music=pd.read_csv('music.csv')
X = music.drop(columns=['genre'])
y= music['genre']
model=DecisionTreeClassifier()
model.fit(X, y)
joblib.dump(model, 'music_recommendation.joblib')
So in output, we will have an array that contains the name of our file.
 You can check the joblib file now in your own desktop as well. This is where our model is stored. It is simply a binary file.
You can check the joblib file now in your own desktop as well. This is where our model is stored. It is simply a binary file.
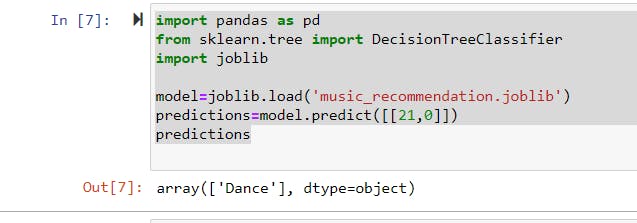
Now, let's try to load our model. We should delete most of the previous code and add a "load" function. And, we can ask it to make predictions like we did before. Final code:
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
import joblib
model=joblib.load('music_recommendation.joblib')
predictions=model.predict([[21,0]])
predictions
Our final result is :